
Build and Host an In-Home AI Conversation Agent with NVIDIA's Powerful RTX Technology
Build and Host an In-Home AI Conversation Agent with NVIDIA’s Powerful RTX Technology
Key Takeaways
- NVIDIA’s Chat with RTX runs locally on your PC, no internet required, with quickly and efficiently.
- To run Chat with RTX, ensure you have RTX 30 series or newer, ample storage (50GB+) and system RAM, and are running Windows 10 or 11, then download and install the files from NVIDIA.
- Chat with RTX can learn from documents and YouTube videos you provide it, then answer questions based on what it learns.
NVIDIA’s Chat with RTX is a lot like ChatGPT, except it runs locally on your own PC, with no need for an Internet connection. It is fast, efficient, and can even learn from documents you provide or YouTube videos. Here’s how to get it running on your PC.
What Do You Need To Run NVIDIA’s Chat With RTX?
Most modern gaming computers will be able to run NVIDIA’s Chat with RTX . Specifically, you will need:
- A 30 series or 40 series RTX (NVIDIA) graphics card with at least 8GB of RAM
- About 50 gigabytes of free storage space
- 16GB of system RAM
- A Windows 10 or Windows 11 PC
Chat with RTX relies on TensorRTX-LLM , which is only supported on 30 series GPUs or newer. That means that your 10 and 20 series GPUs—while still great for many things—are not supported, and likely never will be.
How to Install Chat with RTX
First, download the Chat with RTX files from NVIDIA’s website by clicking the big “Download Now” button towards the top. They’re about 35 gigabytes, so be prepared for it to take a little while.
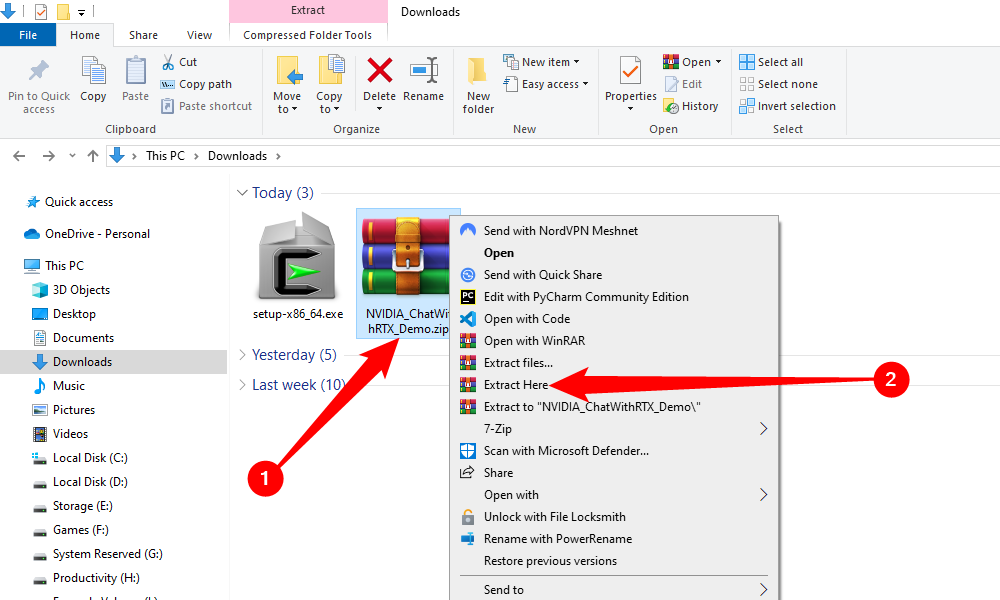
The files come zipped, and you should unzip them before you try to install the application. If you’re using a third-party archival program like 7Zip or WinRAR , you can just right-click the ZIP and select “Extract Here.” If you’re using File Explorer, double-click the zip, copy the “ChatWithRTX_Offline_2_11_mistral_Llama” folder, and then paste it in your Downloads folder (or anywhere else you like).
Once again, be prepared for this operation to take a while—unzipping 35 gigabytes is going to take some time, especially if it is stored on a mechanical hard drive rather than an SSD.
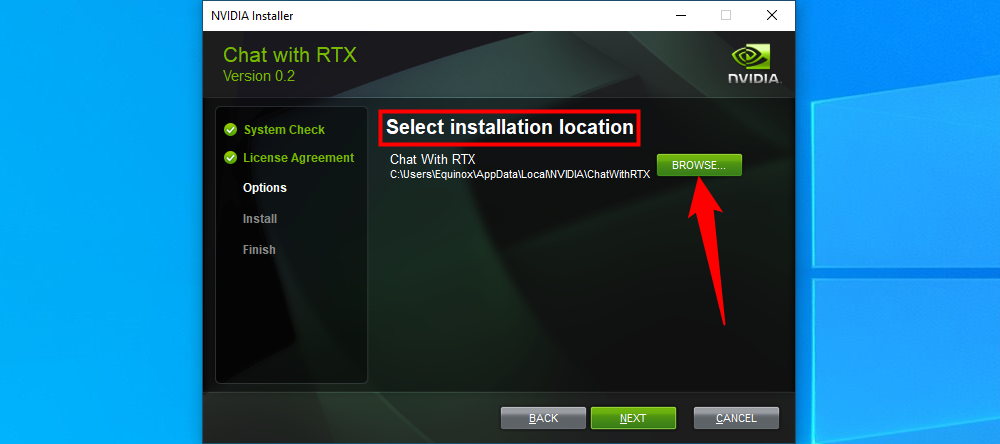
Once it has finished, open up “ChatWithRTX_Offline_2_11_mistral_Llama” and double-click “Setup.exe.” There aren’t many choices you can make in the installer. The only one to watch for is the installation location. Chat with RTX will use up about 50GB when installed, so be sure you pick a drive with enough free space available.
Again, don’t expect this to install super quickly. It has to download additional Python assets before it can run, and those are a few gigabytes each. When it is ready, it should automatically open your browser and display a user interface.
Chat with RTX basically hosts a local web server on your PC to provide a user interface, which you then access through your browser. By default, Chat with RTX is not configured to host a site accessible from the Internet, and the ports used by Chat with RTX are likely closed by default on your router, too. It is not a security risk, or accessible from the Internet, unless you specifically set it up.
If it doesn’t open automatically, check the Terminal (or Command Prompt) window and look for the line “Running on Local URL.” Note the IP address and port, then type that into the address bar of your browser. The IP address will always be 127.0.0.1 (the loopback address ), but the port will change every time you launch Chat with RTX.
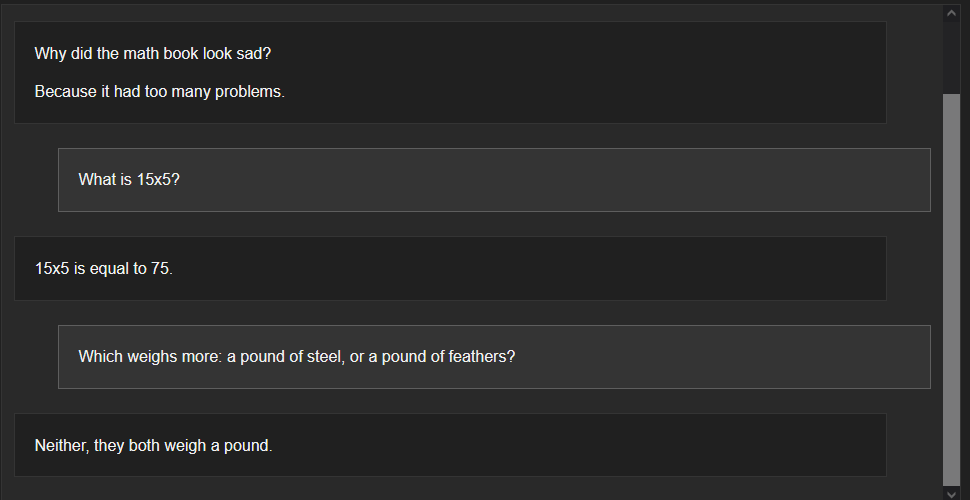
Once Chat with RTX is open in your browser, you can talk with it like you would any other AI chatbot. It can answer basic questions, attempt math, and even tell jokes—and it does so very quickly, too. It is noticeably faster than other locally-run chatbots we’ve tested in the past, no doubt because it can utilize the tensor cores found in NVIDIA RTX GPUs.
However, the really exciting feature is its ability to provide answers based on files or videos you provide.
Make Chat with RTX Learn from Your Files or YouTube
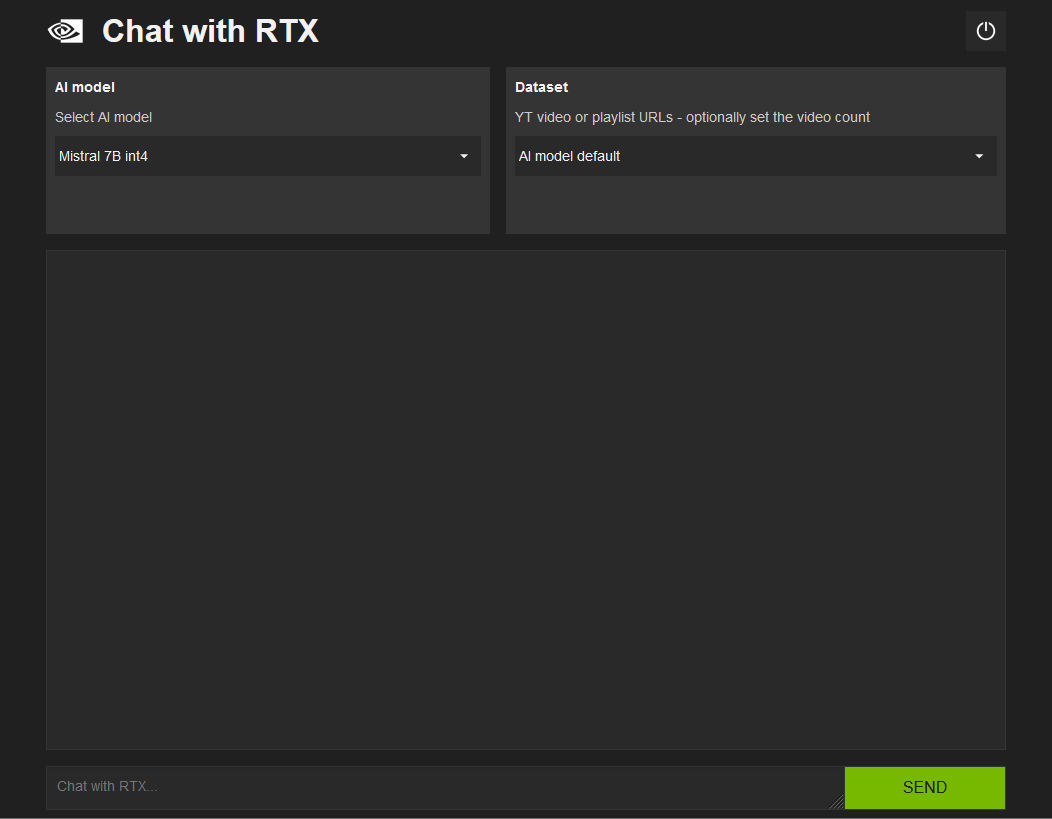
Chat with RTX allows you to provide it with a file or YouTube video from which it can “learn” and generate responses. To specify a file or video, click the drop-down menu below “Dataset,” then select either “Folder Path” or “YouTube URL.”
Select “Folder Path” if you want Chat with RTX to read in a text file or PDF from your PC, and pick YouTube URL if you want to use the transcripts from a YouTube video or playlist.
Keep in mind that it will try to use every text file in the folder you specify, so it is best to create a new folder that only contains the files you want it to pull from.

Processing the new dataset will take time, and the more data you provide, the longer it will take. I tested Chat with RTX on an NVIDIA 3060 12GB GPU, and found that an average novel will finish in less than a minute. Newer and more powerful GPUs will be faster. You can check the Terminal window (it may be Command Prompt if you’re on Windows 10) to see how it is progressing.
However, just because you can feed it all 70 gigabytes of Project Gutenberg in an attempt to turn it into a literary whiz doesn’t mean you should—in fact, I recommend against it. Chat with RTX works best when you don’t mix multiple sources, and when those sources are on the small side.
Chat with RTX Does Hallucinate
Chat with RTX, regardless of which model you use, has the same problem that all AI Chatbots do: it hallucinates . If it doesn’t know something, it will usually confidently declare an answer anyway.
When given the prompt “Who is John Wayne,” Chat with RTX happily told me when he was born and when he died, what genre he was known for, and his iconic roles in “The Duke of Hazzard,” “True Grit,” and “Read Dead Outlaw.”

Of course, John Wayne wasn’t in “The Duke_s_ of Hazzard,” and so far as I can tell, “Red Dead Outlaw” isn’t even a movie—though it does sound like the sort of movie John Wayne would star in.
Chat with RTX seems less given to hallucinations when it doesn’t know something about a file or YouTube video you gave it. It will often state outright that the source you provided doesn’t contain the information you asked about.
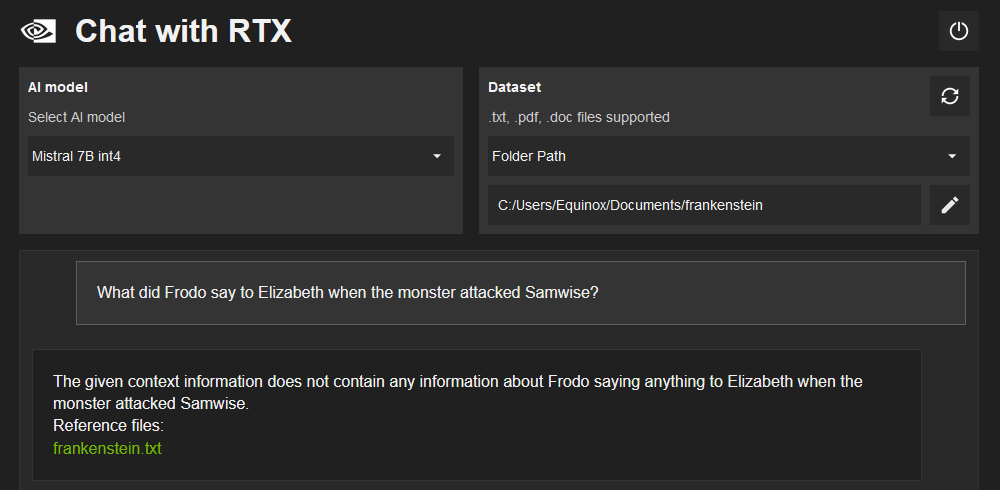
However, sometimes it doesn’t. This becomes more noticeable when you provide more than one file at a time. I pulled “Frankenstein” and “The Raven” from Project Gutenberg and fed them into Chat with RTX, and then asked it why Dr. Frankenstein commanded the monster to eat the raven. It correctly told me that Dr. Frankenstein didn’t command the monster to kill the raven, but then claimed that Dr. Frankenstein was attempting to link his thoughts to the bird’s message.
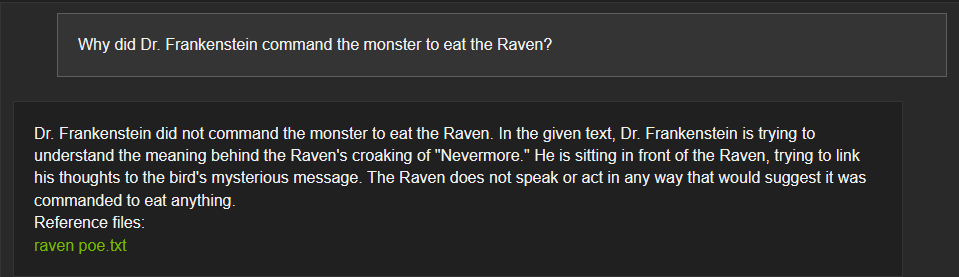
The trouble is that Dr. Frankenstein and the Raven exist in completely separate stories—Chat with RTX just mixed and-matched story elements to get a coherent-sounding answer.
These problems are not unique to Chat with RTX, nor the models it uses, Mistral 7B or Llama 13B. As consumer hardware gets faster and sophisticated models become more optimized, the technology will become more reliable. For now, if you keep things simple and don’t overload it with information, Chat with RTX can provide an interesting and helpful way to interact with documents. Just remember to treat everything it tells you with a bit of skepticism.
- Title: Build and Host an In-Home AI Conversation Agent with NVIDIA's Powerful RTX Technology
- Author: Jeffrey
- Created at : 2024-08-28 22:58:27
- Updated at : 2024-08-29 11:23:46
- Link: https://some-knowledge.techidaily.com/build-and-host-an-in-home-ai-conversation-agent-with-nvidias-powerful-rtx-technology/
- License: This work is licensed under CC BY-NC-SA 4.0.