Downloading Files with cURL in a Linux Shell Environment
Downloading Files with cURL in a Linux Shell Environment
Quick Links
- curl vs. wget : What’s the Difference?
- How to Install curl
- The curl Version
- Retrieving a Web Page with curl
- Saving Data to a File
- Using a Progress Bar To Monitor Downloads
- Restarting an Interrupted Download
- Retrieving HTTP headers
- Downloading Multiple URLs
- Downloading Files From an FTP Server
- Sending Parameters to Remote Servers
- Sometimes curl, Sometimes wget
The Linux curl command can do a whole lot more than download files. Find out what curl is capable of, and when you should use it instead of wget.
curl vs. wget : What’s the Difference?
People often struggle to identify the relative strengths of the wget and curl commands . The commands do have some functional overlap. They can each retrieve files from remote locations, but that’s where the similarity ends.
wget is a fantastic tool for downloading content and files . It can download files, web pages, and directories. It contains intelligent routines to traverse links in web pages and recursively download content across an entire website. It is unsurpassed as a command-line download manager.
curl satisfies an altogether different need . Yes, it can retrieve files, but it cannot recursively navigate a website looking for content to retrieve. What curl actually does is let you interact with remote systems by making requests to those systems, and retrieving and displaying their responses to you. Those responses might well be web page content and files, but they can also contain data provided via a web service or API as a result of the “question” asked by the curl request.
And curl isn’t limited to websites. curl supports over 20 protocols, including HTTP, HTTPS, SCP, SFTP, and FTP. And arguably, due to its superior handling of Linux pipes, curl can be more easily integrated with other commands and scripts.
The author of curl has a webpage that describes the differences he sees between curl and wget.
How to Install curl
Out of the computers used to research this article, Fedora 31 and Manjaro 18.1.0 had curl already installed. curl had to be installed on Ubuntu 18.04 LTS. On Ubuntu, run this command to install it:
sudo apt-get install curl

 Lyric Video Creator Professional Version
Lyric Video Creator Professional Version
The curl Version
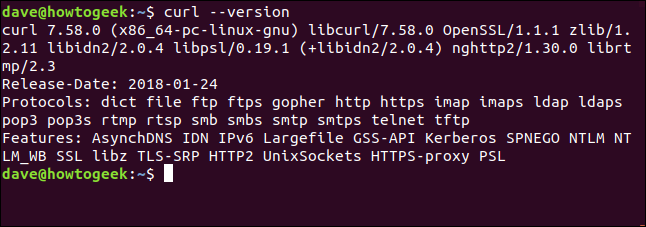
The --version option makes curlreport its version. It also lists all the protocols that it supports.
curl –version

Retrieving a Web Page with curl
If we point curl at a web page, it will retrieve it for us.
curl https://www.bbc.com


But its default action is to dump it to the terminal window as source code.
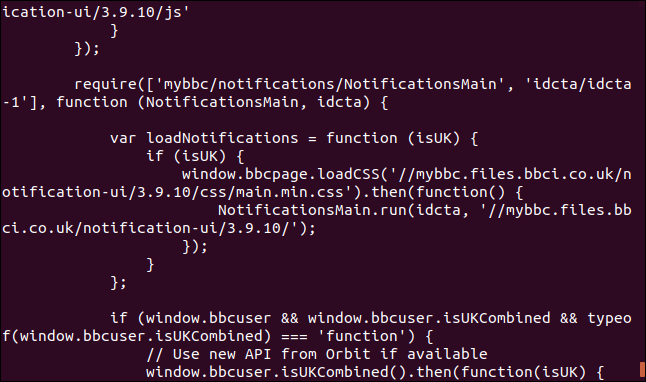

If you don’t tell curl you want something stored as a file, it will always dump it to the terminal window. If the file it is retrieving is a binary file, the outcome can be unpredictable. The shell may try to interpret some of the byte values in the binary file as control characters or escape sequences.
Saving Data to a File
Let’s tell curl to redirect the output into a file:
curl https://www.bbc.com > bbc.html

 PaperScan Professional: PaperScan Scanner Software is a powerful TWAIN & WIA scanning application centered on one idea: making document acquisition an unparalleled easy task for anyone.
PaperScan Professional: PaperScan Scanner Software is a powerful TWAIN & WIA scanning application centered on one idea: making document acquisition an unparalleled easy task for anyone. This time we don’t see the retrieved information, it is sent straight to the file for us. Because there is no terminal window output to display, curl outputs a set of progress information.
It didn’t do this in the previous example because the progress information would have been scattered throughout the web page source code, so curl automatically suppressed it.
In this example, curl detects that the output is being redirected to a file and that it is safe to generate the progress information.
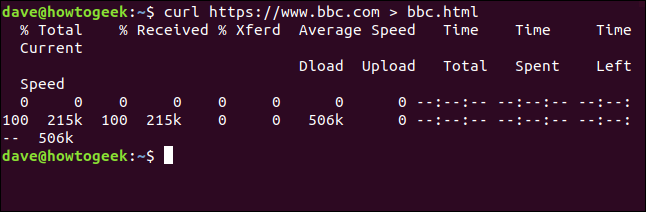
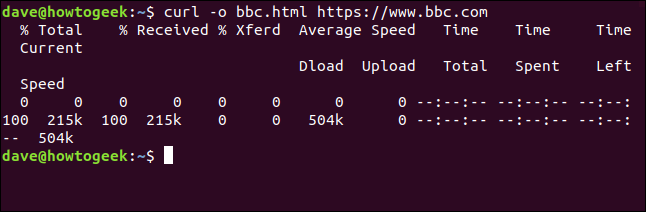
The information provided is:
- % Total: The total amount to be retrieved.
- % Received: The percentage and actual values of the data retrieved so far.
- % Xferd: The percent and actual sent, if data is being uploaded.
- Average Speed Dload: The average download speed.
- Average Speed Upload: The average upload speed.
- Time Total: The estimated total duration of the transfer.
- Time Spent: The elapsed time so far for this transfer.
- Time Left: The estimated time left for the transfer to complete
- Current Speed: The current transfer speed for this transfer.
Because we redirected the output from curl to a file, we now have a file called “bbc.html.”
Double-clicking that file will open your default browser so that it displays the retrieved web page.
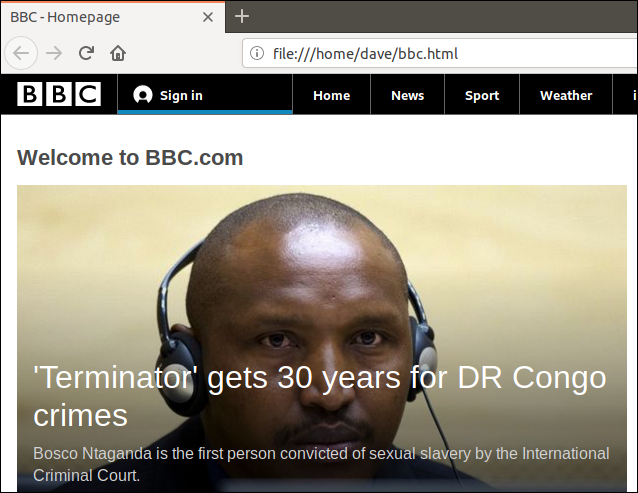
Note that the address in the browser address bar is a local file on this computer, not a remote website.
We don’t have to redirect the output to create a file. We can create a file by using the -o (output) option, and telling curl to create the file. Here we’re using the -o option and providing the name of the file we wish to create “bbc.html.”
curl -o bbc.html https://www.bbc.com
Using a Progress Bar To Monitor Downloads
To have the text-based download information replaced by a simple progress bar, use the -# (progress bar) option.
curl -x -o bbc.html https://www.bbc.com


Restarting an Interrupted Download
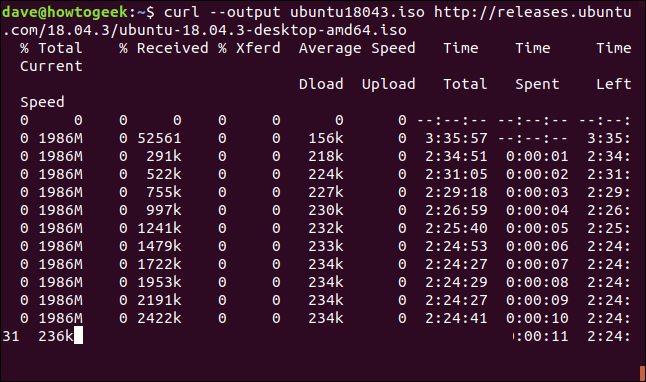
It is easy to restart a download that has been terminated or interrupted. Let’s start a download of a sizeable file. We’ll use the latest Long Term Support build of Ubuntu 18.04. We’re using the --output option to specify the name of the file we wish to save it into: “ubuntu180403.iso.”
curl –output ubuntu18043.iso http://releases.ubuntu.com/18.04.3/ubuntu-18.04.3-desktop-amd64.iso


The download starts and works its way towards completion.
If we forcibly interrupt the download with Ctrl+C , we’re returned to the command prompt, and the download is abandoned.
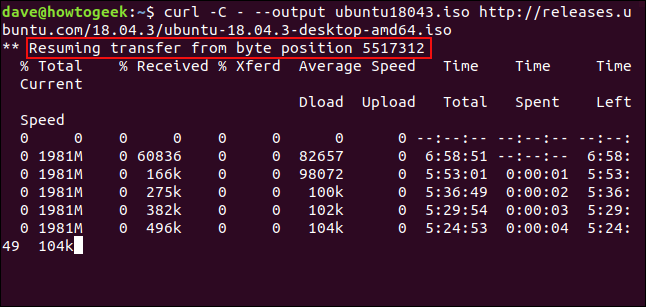
To restart the download, use the -C (continue at) option. This causes curl to restart the download at a specified point or offset within the target file. If you use a hyphen - as the offset, curl will look at the already downloaded portion of the file and determine the correct offset to use for itself.
curl -C - –output ubuntu18043.iso http://releases.ubuntu.com/18.04.3/ubuntu-18.04.3-desktop-amd64.iso

The download is restarted. curl reports the offset at which it is restarting.
Retrieving HTTP headers
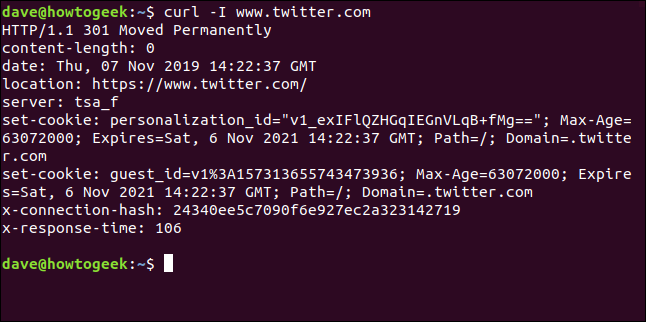
With the -I (head) option, you can retrieve the HTTP headers only. This is the same as sending the HTTP HEAD command to a web server.
curl -I www.twitter.com

This command retrieves information only; it does not download any web pages or files.

Downloading Multiple URLs
Using xargs we can download multiple URLs at once. Perhaps we want to download a series of web pages that make up a single article or tutorial.
Copy these URLs to an editor and save it to a file called “urls-to-download.txt.” We can use xargs to treat the content of each line of the text file as a parameter which it will feed to curl, in turn.
https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#0
https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#1
https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#2
https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#3
https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#4
https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#5
This is the command we need to use to have xargs pass these URLs to curl one at a time:
xargs -n 1 curl -O < urls-to-download.txt
Note that this command uses the -O (remote file) output command, which uses an uppercase “O.” This option causes curl to save the retrieved file with the same name that the file has on the remote server.
The -n 1 option tells xargs to treat each line of the text file as a single parameter.
When you run the command, you’ll see multiple downloads start and finish, one after the other.
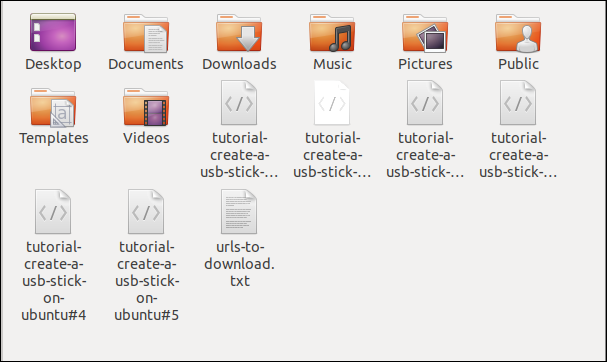
Checking in the file browser shows the multiple files have been downloaded. Each one bears the name it had on the remote server.

Downloading Files From an FTP Server
Using curl with a File Transfer Protocol (FTP) server is easy, even if you have to authenticate with a username and password. To pass a username and password with curl use the -u (user) option, and type the username, a colon “:”, and the password. Don’t put a space before or after the colon.
This is a free-for-testing FTP server hosted by Rebex . The test FTP site has a pre-set username of “demo”, and the password is “password.” Don’t use this type of weak username and password on a production or “real” FTP server.
curl -u demo:password ftp://test.rebex.net

curl figures out that we’re pointing it at an FTP server, and returns a list of the files that are present on the server.

The only file on this server is a “readme.txt” file, of 403 bytes in length. Let’s retrieve it. Use the same command as a moment ago, with the filename appended to it:
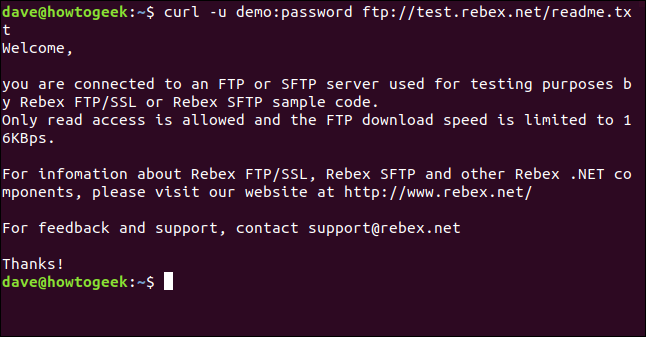
curl -u demo:password ftp://test.rebex.net/readme.txt

The file is retrieved and curl displays its contents in the terminal window.
 OtsAV TV Webcaster
OtsAV TV Webcaster In almost all cases, it is going to be more convenient to have the retrieved file saved to disk for us, rather than displayed in the terminal window. Once more we can use the -O (remote file) output command to have the file saved to disk, with the same filename that it has on the remote server.
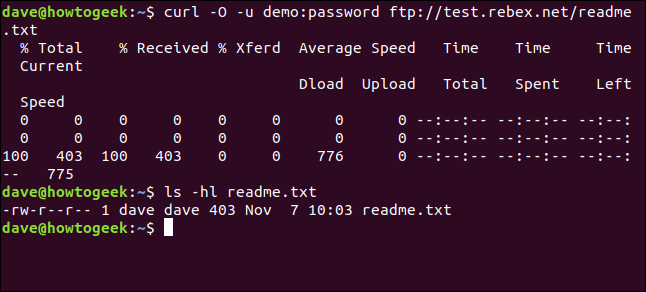
curl -O -u demo:password ftp://test.rebex.net/readme.txt

The file is retrieved and saved to disk. We can use ls to check the file details. It has the same name as the file on the FTP server, and it is the same length, 403 bytes.
ls -hl readme.txt
 Easy GIF Animator is a powerful animated GIF editor and the top tool for creating animated pictures, banners, buttons and GIF videos. You get extensive animation editing features, animation effects, unmatched image quality and optimization for the web. No other GIF animation software matches our features and ease of use, that’s why Easy GIF Animator is so popular.
Easy GIF Animator is a powerful animated GIF editor and the top tool for creating animated pictures, banners, buttons and GIF videos. You get extensive animation editing features, animation effects, unmatched image quality and optimization for the web. No other GIF animation software matches our features and ease of use, that’s why Easy GIF Animator is so popular.Sending Parameters to Remote Servers
Some remote servers will accept parameters in requests that are sent to them. The parameters might be used to format the returned data, for example, or they may be used to select the exact data that the user wishes to retrieve. It is often possible to interact with web application programming interfaces (APIs) using curl.
As a simple example, the ipify website has an API can be queried to ascertain your external IP address.
By adding the format parameter to the command, with the value of “json” we can again request our external IP address, but this time the returned data will be encoded in the JSON format .
curl https://api.ipify.org?format=json

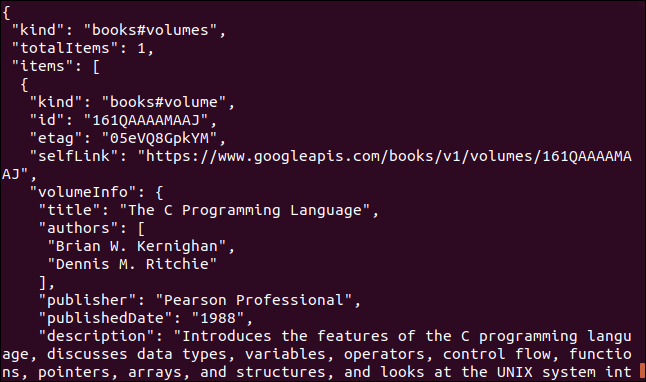
Here’s another example that makes use of a Google API. It returns a JSON object describing a book. The parameter you must provide is the International Standard Book Number (ISBN) number of a book. You can find these on the back cover of most books, usually below a barcode. The parameter we’ll use here is “0131103628.”
curl https://www.googleapis.com/books/v1/volumes?q=isbn:0131103628

 Any DRM Removal for Mac: Remove DRM from Adobe, Kindle, Sony eReader, Kobo, etc, read your ebooks anywhere.
Any DRM Removal for Mac: Remove DRM from Adobe, Kindle, Sony eReader, Kobo, etc, read your ebooks anywhere.The returned data is comprehensive:
Sometimes curl, Sometimes wget
If I wanted to download content from a website and have the tree-structure of the website searched recursively for that content, I’d use wget.
If I wanted to interact with a remote server or API, and possibly download some files or web pages, I’d use curl. Especially if the protocol was one of the many not supported by wget.
| | Linux Commands | | |
| —————– | ———————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————— | |
| Files | tar · pv · cat · tac · chmod · grep · diff · sed · ar · man · pushd · popd · fsck · testdisk · seq · fd · pandoc · cd · $PATH · awk · join · jq · fold · uniq · journalctl · tail · stat · ls · fstab · echo · less · chgrp · chown · rev · look · strings · type · rename · zip · unzip · mount · umount · install · fdisk · mkfs · rm · rmdir · rsync · df · gpg · vi · nano · mkdir · du · ln · patch · convert · rclone · shred · srm · scp · gzip · chattr · cut · find · umask · wc · tr | |
| Processes | alias · screen · top · nice · renice · progress · strace · systemd · tmux · chsh · history · at · batch · free · which · dmesg · chfn · usermod · ps · chroot · xargs · tty · pinky · lsof · vmstat · timeout · wall · yes · kill · sleep · sudo · su · time · groupadd · usermod · groups · lshw · shutdown · reboot · halt · poweroff · passwd · lscpu · crontab · date · bg · fg · pidof · nohup · pmap | |
| Networking | netstat · ping · traceroute · ip · ss · whois · fail2ban · bmon · dig · finger · nmap · ftp · curl · wget · who · whoami · w · iptables · ssh-keygen · ufw · arping · firewalld | |
- Title: Downloading Files with cURL in a Linux Shell Environment
- Author: Jeffrey
- Created at : 2024-08-30 09:03:44
- Updated at : 2024-08-31 09:03:44
- Link: https://some-knowledge.techidaily.com/downloading-files-with-curl-in-a-linux-shell-environment/
- License: This work is licensed under CC BY-NC-SA 4.0.